Reflections on Reflector: Challenges in embedding web content

Cyrillic alphabet
Learning a language is fun, but not easy. Enrolling in classroom or online courses and conversing with native-speaker friends are a few of the many paths to language proficiency. There is also no shortage of self-guided, tech-enabled tools to augment these traditional methods. Duolingo gamifies language learning. Memrise leverages “spaced-repetition” to help cement vocabulary and grammar.
Reading foreign news, blog posts, and other kinds of articles is an effective way to practically improve one’s foreign language comprehension. Not only is consuming text articles a practical use case for learning a new language, reputable publishers can also be relied on to employ standard language conventions, including proper spelling and grammar, as well as a healthy dose of colloquialisms. Is it then possible to leverage technology to ease the painstaking exercise of manual back-and-forth translation of this kind of web content?
Reflector was intended to display translated and untranslated webpages side-by-side in a single browser window through content embedding. Users can read and compare the original and translated versions of any web page without having to manage multiple browser tabs or windows. In addition, dynamic URL generation of specific pages allowed users to “bookmark” and share links with others.

Reflector — expectation
The MVP worked well in a local development environment, as well as (still inexplicably) on some desktops in a publicly deployed environment. However, when viewed on certain laptops, a reader would see the following:
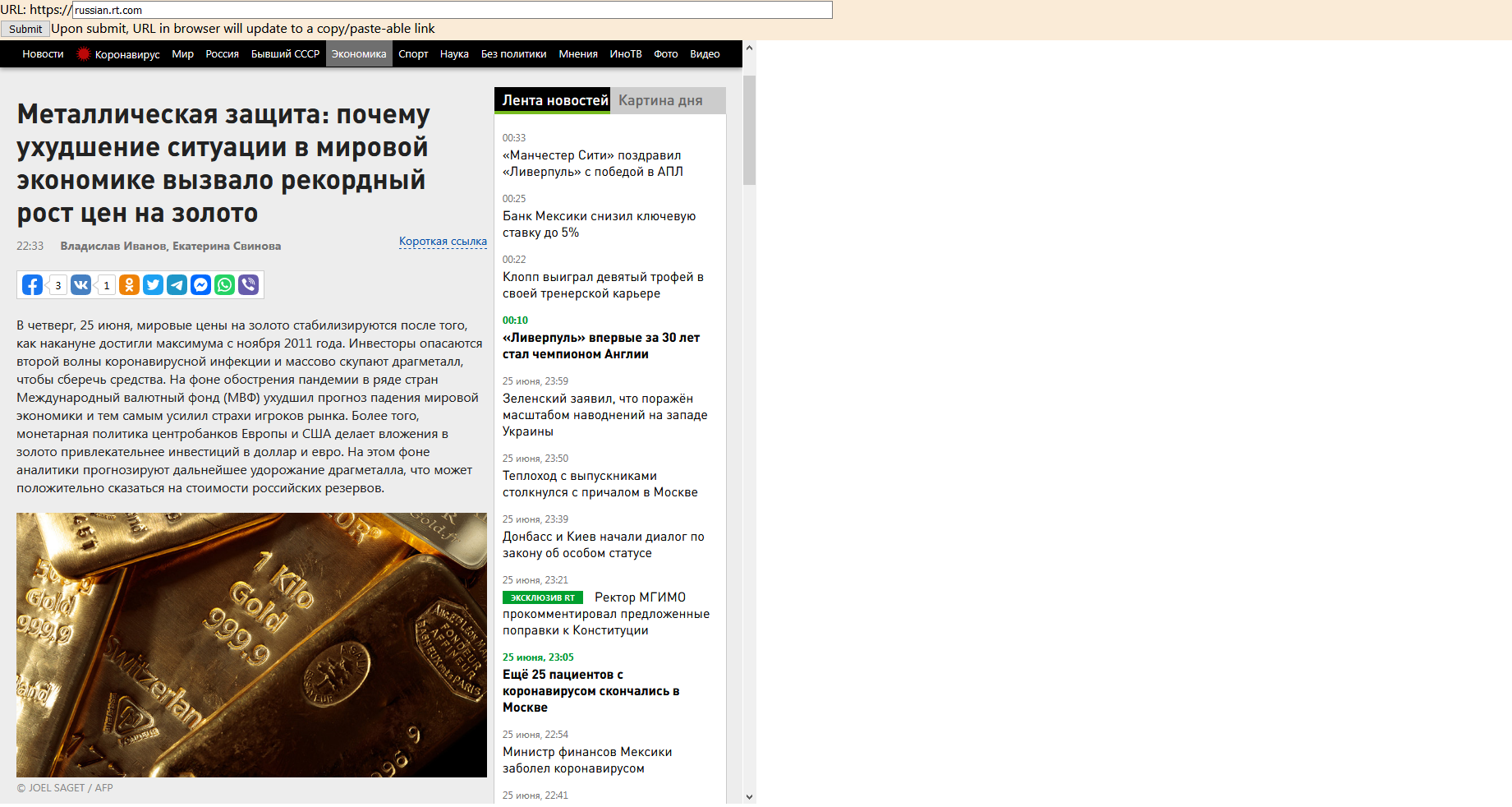
Reflector — reality
Why did Reflector not behave as intended? Why does the embedded Google-translated page on the right not show up?
The key to these questions lies in the mechanism by which these webpages are embedded. Individual pages, in Reflector’s case the original language article on the left and the translated content on the right, can be embedded inside the host webpage using <iframe>, <embed>, and <object> HTML elements. Each implementation has its pros and cons depending on the use case.
Embedded pages share a common rule to which they are subject — the X-Frame-Options HTTP response header. This header has two directives. SAMEORIGIN allows a page to be embedded only if the host page is from the same origin (e.g., Google pages can only be embedded on other Google pages). DENY prevents a page from being embedded by any host. The absence of the X-Frame-Options header implies that the page can be freely embedded by any other page.
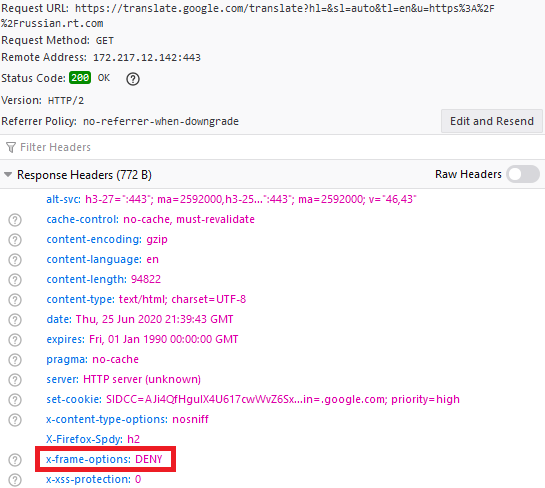
“Network” tab in browser console showing X-Frame-Options
In Reflector’s case, untranslated webpages each have their own X-Frame-Options directive depending on the policy of the owner. In contrast, Google Translate’s whole-page translation output always includes the DENY directive. Thus, the embedded Google-translated page is not displayed, or is replaced by a browser-generated page explaining why the embedding failed. It is still a mystery to me why in some instances translated pages seem to be able to bypass embedding restrictions and successfully display, such as during local development on localhost and on some desktop PCs when visiting reflector.yifanchen.io.
Why do some websites forbid their content from being embedded on other websites? First, embedded content creates security risks, including enabling “clickjacking”, facilitating cross-site scripting (XSS) attacks, and opening channels to deliver malware. Second, a non-security concern is that embedded content can easily be appropriated by and misconstrued as belonging to the host webpage. Websites with restrictive embedding policies deem these liabilities as outweighing the benefits of allowing their content to be embedded.
Embedded content has its own set of safeguards to minimize the attack surface for exploits. For example, information flow between host and embedded pages is tightly restricted to limit the hijacking of sensitive data. Reflector was intended to include concurrent sentence highlighting, coordinated scrolling, and other features that required communication between embedded pages. However, such features were difficult to implement given the security-driven isolation and compartmentalization of embedded content.
Overall, building Reflector was a great way to get back into coding and re-acclimate to the challenges of web development. There could be clever solutions for easy comparative article translation, such as using Instapaper-like article parsing to translate only the relevant article text without having to translate and embed entire pages. For now, perhaps it’s fine to do it the old-fashioned way: opening up two browser windows side-by-side.
Special thanks to Kirill Pesterev for feedback and testing on Reflector. Check out his Russian language blog Верблюд-Стоик (Stoic Camel) — a collection of notes and thoughts about life, business, economics, philosophy, science, books and finding answers to the questions “How to live?” and “What to do?”